归档是一种将不常使用的数据从主数据库中移除的技术。通过归档,我们可以减少数据库存储空间,提高系统性能,降低存储成本,增加可用空间,提高数据安全性,提高数据准确性和可靠性。
随着企业数据量的不断增加,数据管理和存储已经成为一个重要的问题。而对于使用 Salesforce 服务更是如此,Salesforce Big Objects 是一种特殊数据对象,旨在解决企业面临的存储和管理数据的挑战。可以帮助企业存储和管理大量的历史数据。与传统的 Salesforce 对象不同,Big Objects 可以存储超过亿级的数据记录,并且可以快速读取和查询这些数据。本文将探讨如何使用 Salesforce Big Objects 进行数据归档,以获得最佳的数据管理效果。
那么使用 Salesforce Big Objects 归档数据到底可以解决什么问题呢?
- 提高系统性能:通过归档不常使用的数据,可以减小数据库的负荷,提升系统性能。
- 降低存储成本:通过归档数据,可以减小数据库存储空间,降低存储成本。
- 提高数据安全:通过归档数据,可以提高数据的安全性,防止数据泄露。
- 提升数据治理:通过归档数据,可以更好地管理数据,提高数据的准确性和可靠性。
数据归档/备份在 Salesforce 中的几个方案?
为什么数据归档这么重要?
大数据量会导致查询性能下降并影响用户体验。通过清理不需要的数据,您可以减少数据混乱并提高数据采用率。归档使您的组织能够更好地控制您的数据信息。还可以通过归档 Salesforce 数据来降低存储成本。最后但并非最不重要的一点是,归档可确保您的数据安全。
除了 Big Object, Salesforce 还有哪些数据归档/备份的方案?
- Shadow Objects: 它不是一个官方或正式使用的术语,是一个自定义对象,用于复制主对象的记录。它将拥有与主对象相同的结构。意味着有同样的字段,同样的 CRUD,OWD, 字段级安全。我们可以根据标准将记录转移到这个新对象。通过这种方式,我们可以减少主对象的数量。比如:可以使用 Case 对象作为主对象。任何被创建或更新的 Case 记录都会被复制到 Shadow_Case__c (Shadow) 对象。但是如果比较在意数据 storage 空间的话,这种备份方式不推荐。
- Heroku: 基于云的服务,将数据存入或转出 Salesforce 到 Heroku(Postgres). 使用 Salesforce 和 Heroku Postgres 之间的双向同步,通过 Heroku Connect 将您 Postgres 数据库中的数据与 Salesforce 数据库中的 Contact, Account 等标准对象和其他自定义对象统一起来。
- App exchange 产品: 最受欢迎的备份数据的 Appexchange 产品是:Backupify, Ownbackup for Salesforce, Spanning Backup, Odaseva.
- External Objects: 类似于 Salesforce 中的自定义对象,但外部对象的记录数据是存储在您的 Salesforce 组织之外。每个外部对象都与您的 Salesforce 组织中的一个外部数据源定义相关。外部数据源规定了如何访问外部系统。比如:可以使用 Azure 作为外部数据源将数据同步至 Salesforce.
创建 Big Object
这篇文章的 Demo 会以 Case 对象为例,支持通过 Big Object 对 Case 数据进行归档。您可以在 Salesforce 的 Setup 中创建一个自定义的 Big Object. 你也可以用 Metadata API 创建一个自定义的 Big Object,但在通过 Setup 中创建要比 API 要简单得多。
在 Salesforce Setup 中,在查找框中输入 Big Object,然后选择点击 Big Object.
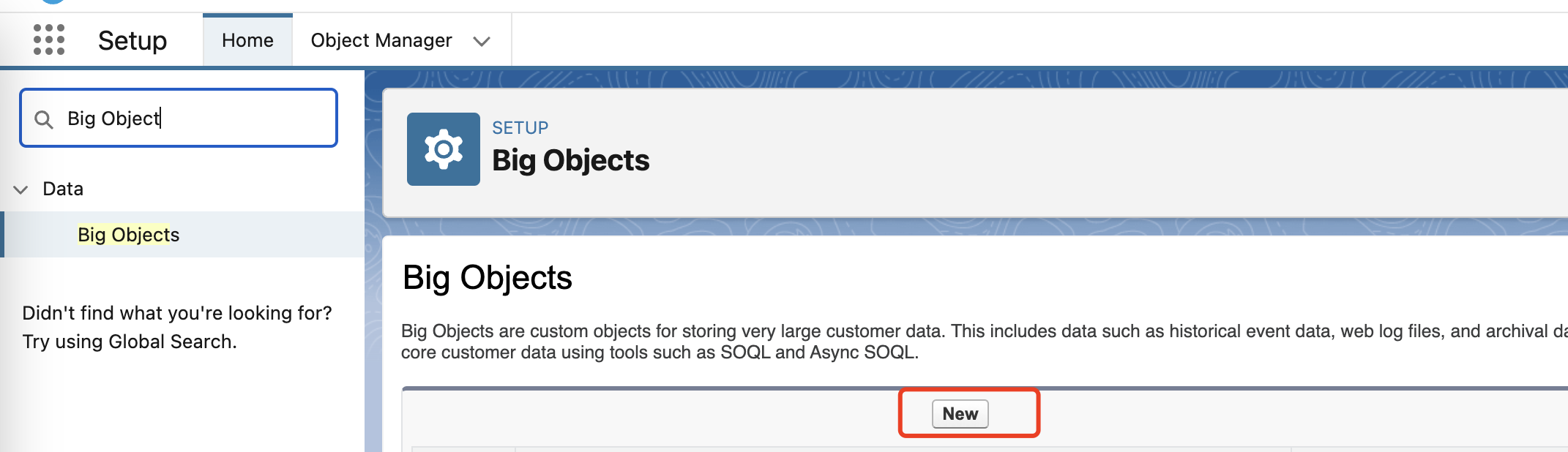
创建一个名为 Case__b 的 Big Object.
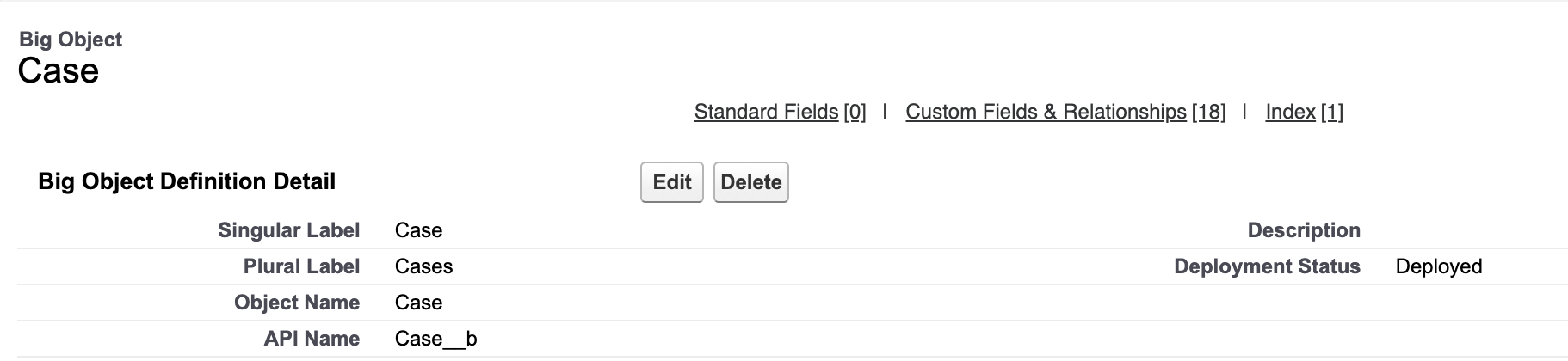
创建自定义字段
一旦你定义了你的 Big Object,可以继续添加自定义字段。自定义字段为您的 Big Object 存储独特的数据。Big Object 支持这些字段类型:
- Lookup Relationship
- Date/Time
- Number
- Phone
- Text
- Text Area (Long)
- URL
Case__b 对象字段创建如下,其中 Account 和 Contact 对象和 Case 有关联,我们通过存储对象的 ID 作为唯一标识,这里面会将其作为 Index 来提高查询效率。
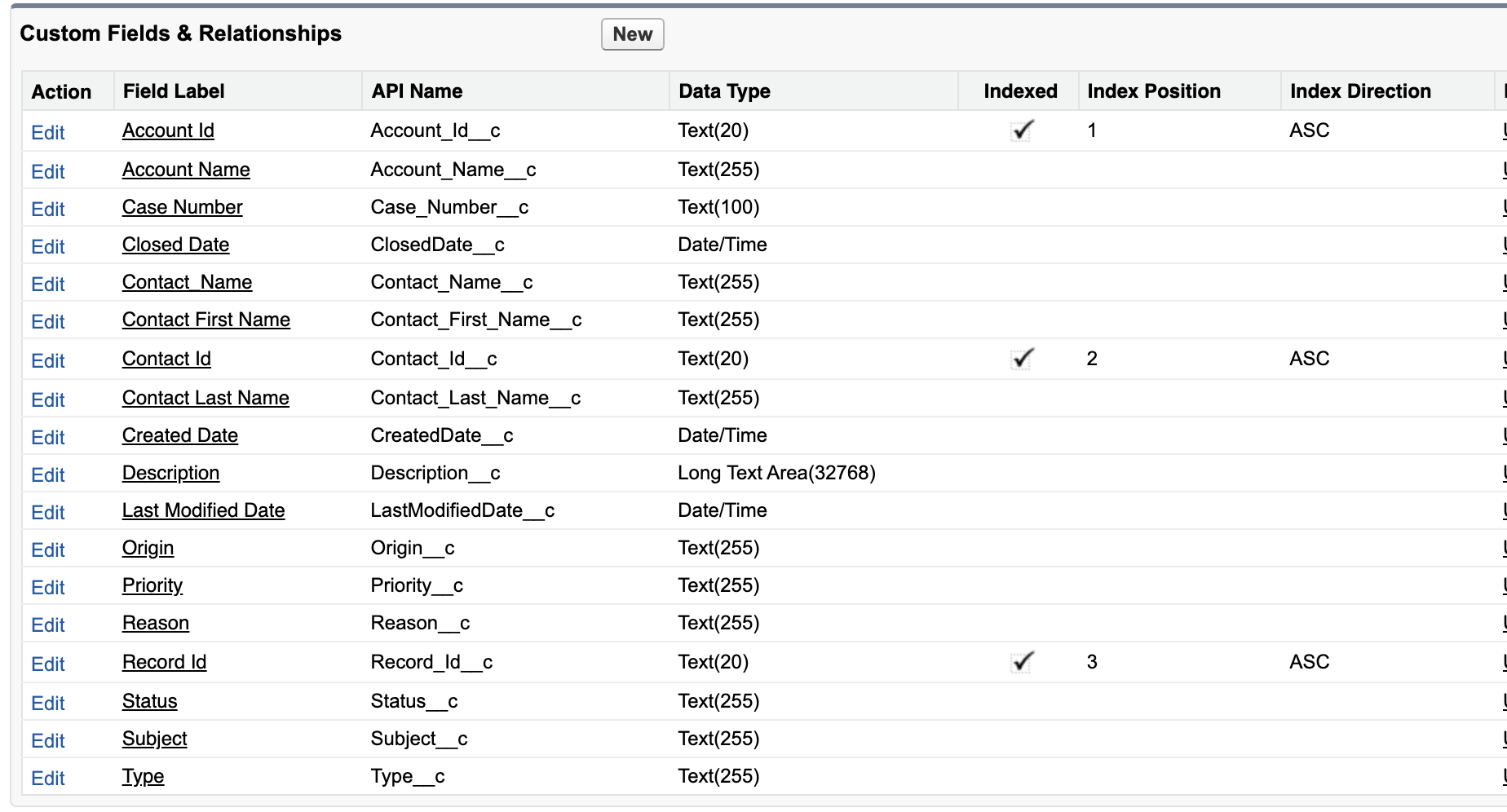
创建自定义的 Big Object 索引
这个很重要!Big Object 的索引中定义的字段决定了 Big Object 被查询的能力。在你的索引中定义的字段应该是与你的查询最相关的字段,所以你在配置索引的时候要有远见,你定义字段的顺序也是一个重要的考虑因素。如果你使用 SOQL 来查询 Big Object, 你只能按照你定义的顺序来查询组成你的索引的字段。将你在 query filter 中最常使用的字段分配到你的索引中的第一个位置。
定义索引时的注意事项:
- 一个索引必须包括至少一个自定义字段,最多可以有五个自定义字段。
- 包含在索引中的自定义字段必须被标记为必填。
- 长文本区字段不能包括在索引中。
- 索引中所有文本字段的总字符数不能超过 100.
- 一旦你创建了一个索引,就不能编辑或删除它。要改变索引,请新创建另一个 Big Object 再添加索引。
实现操作界面
需求:希望可以在 Case 详情页面提供 Archive 功能,通过触发 Archive 操作数据自动删除并归档,并且能够在 Account 和 Contact 界面查看到已归档的 Case 数据。本次 Demo 演示的是如何归档单条 Case 记录,暂不支持批量归档 Case 记录,不过实现逻辑与此大同小异,读者可自行实现。
部分 Apex 代码:
CaseArchiveController.cls
将主数据 Case 记录转为 Big Object, 并删除主数据的记录。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
//查询主数据
Case caseS = [
SELECT
Id,
ContactId,
AccountId,
CaseNumber,
CreatedDate,
...
FROM Case WHERE Id = :recordId
];
// 将 Case 数据转换为 BigObject
Case__b caseB = new Case__b();
caseB.Record_Id__c = caseS.Id;
caseB.Case_Number__c = caseS.CaseNumber;
caseB.Account_Id__c = caseS.AccountId;
caseB.Contact_Id__c = caseS.ContactId;
...
Database.SaveResult result = Database.insertImmediate(caseB);
delete caseS;
部分 lwc 实现逻辑:
caseArchive.html
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
<template>
<div class="slds-card slds-p-around_medium" style="text-align:center;">
<template if:true={showArchive}>
<lightning-button variant="brand" label="Archive Case" onclick={archiveClick} class="slds-p-around_medium"></lightning-button>
</template>
<template if:true={showSuccess}>
<div class="slds-text-heading_small slds-p-bottom_small">Case archived and deleted!</div>
<div class="slds-text-body_regular slds-p-bottom_medium">To retrieve this case, navigate to the related Account or Contact record.</div>
<div>
<lightning-button label="View the Account" onclick={navigateToAccount} class="slds-p-around_xx-small"></lightning-button>
<lightning-button label="View the Contact" onclick={navigateToContact} class="slds-p-around_xx-small"></lightning-button>
</div>
</template>
</div>
</template>
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
import { LightningElement, api, wire } from 'lwc';
import { getRecord } from 'lightning/uiRecordApi';
import { NavigationMixin } from 'lightning/navigation';
import callArchiveCase from '@salesforce/apex/CaseArchiveController.archiveCase';
export default class CaseArchive extends NavigationMixin(LightningElement) {
@api recordId;
showArchive = true;
showSuccess = false;
@wire(getRecord, { recordId: '$recordId', fields: ['Case.AccountId', 'Case.ContactId'] })
record;
archiveClick(event) {
callArchiveCase({
'recordId': this.recordId
})
.then(result => {
this.showArchive = false;
this.showSuccess = true;
})
.catch(error => {
console.log('ERROR: ' + JSON.stringify(error));
});
}
navigateToAccount(event) {
this[NavigationMixin.Navigate]({
type: 'standard__recordPage',
attributes: {
recordId: this.record.data.fields.AccountId.value,
actionName: 'view'
}
});
}
navigateToContact(event) {
this[NavigationMixin.Navigate]({
type: 'standard__recordPage',
attributes: {
recordId: this.record.data.fields.ContactId.value,
actionName: 'view'
}
});
}
}
操作界面如下:Case Detail -> 点击 Archive Case 按钮
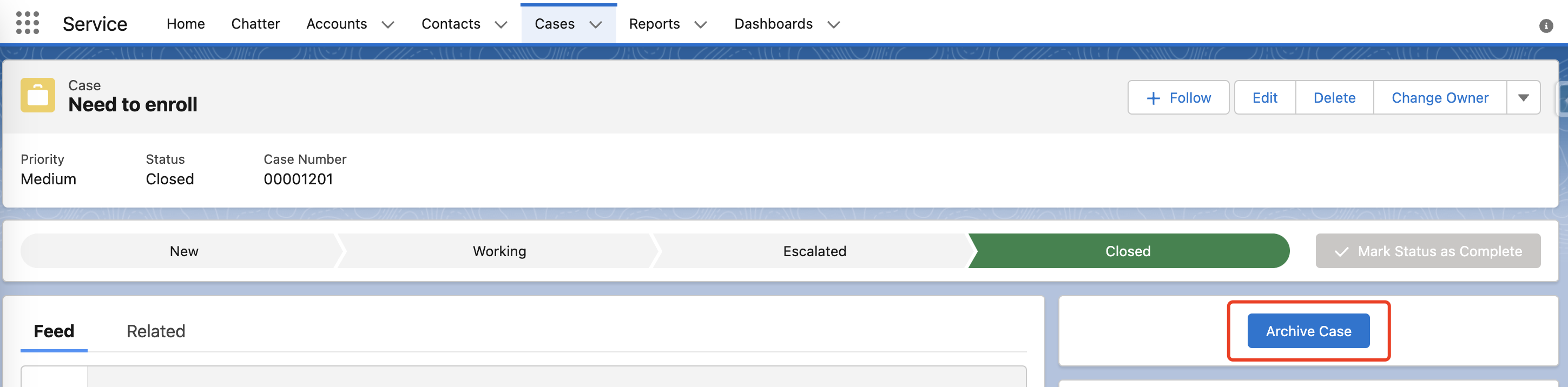
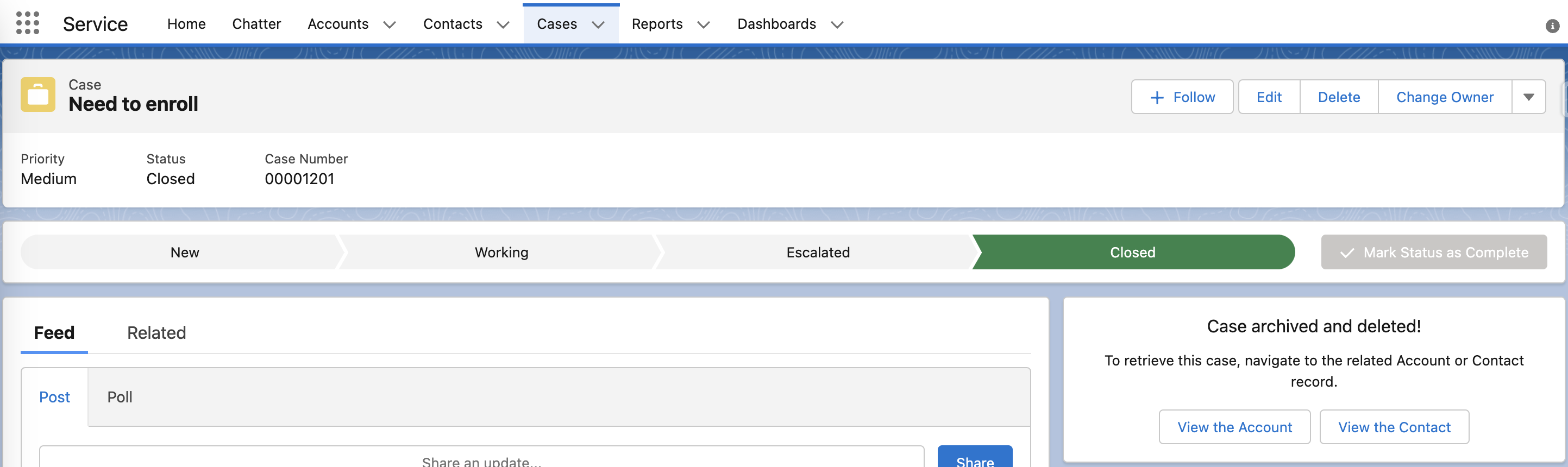
在 Account 上查看归档数据
由于 Case 归档后,原始数据已经删除,那么我们可以通过其他对象来查看已归档数据,还记得我们在创建 Big object 的时候,创建了 Account 和 Contact Id 字段,并创建了索引,我们可以通过这些字段查看归档的 Case 数据。
获取归档的 Case 记录相关逻辑代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
// 如果有一个联系人 ID,但没有 account ID,可以通过查询获取它。
if ( String.isBlank(accountId) && !String.isBlank(contactId) ) {
Contact contact = [SELECT AccountId FROM Contact WHERE Id = :contactId];
accountId = contact.AccountId;
}
List<Case__b> cases;
List<String> columns = new List<String>{'Record_Id__c', 'Account_Id__c', 'Contact_Id__c', 'Subject__c', ... };
String query = 'SELECT ';
for (Integer i = 0; i < columns.size(); i++) {
query = query + columns[i];
if (i < (columns.size() - 1)) {
query = query + ', ';
}
}
query = query + ' FROM Case__b';
// Filter by Account ID
if (!String.isBlank(accountId)) {
query = query + ' WHERE Account_Id__c = :accountId';
}
// Filter by Contact ID
if (!String.isBlank(contactId)) {
query = query + ' AND Contact_Id__c = :contactId';
}
query = query + ' LIMIT 30';
cases = Database.query(query);
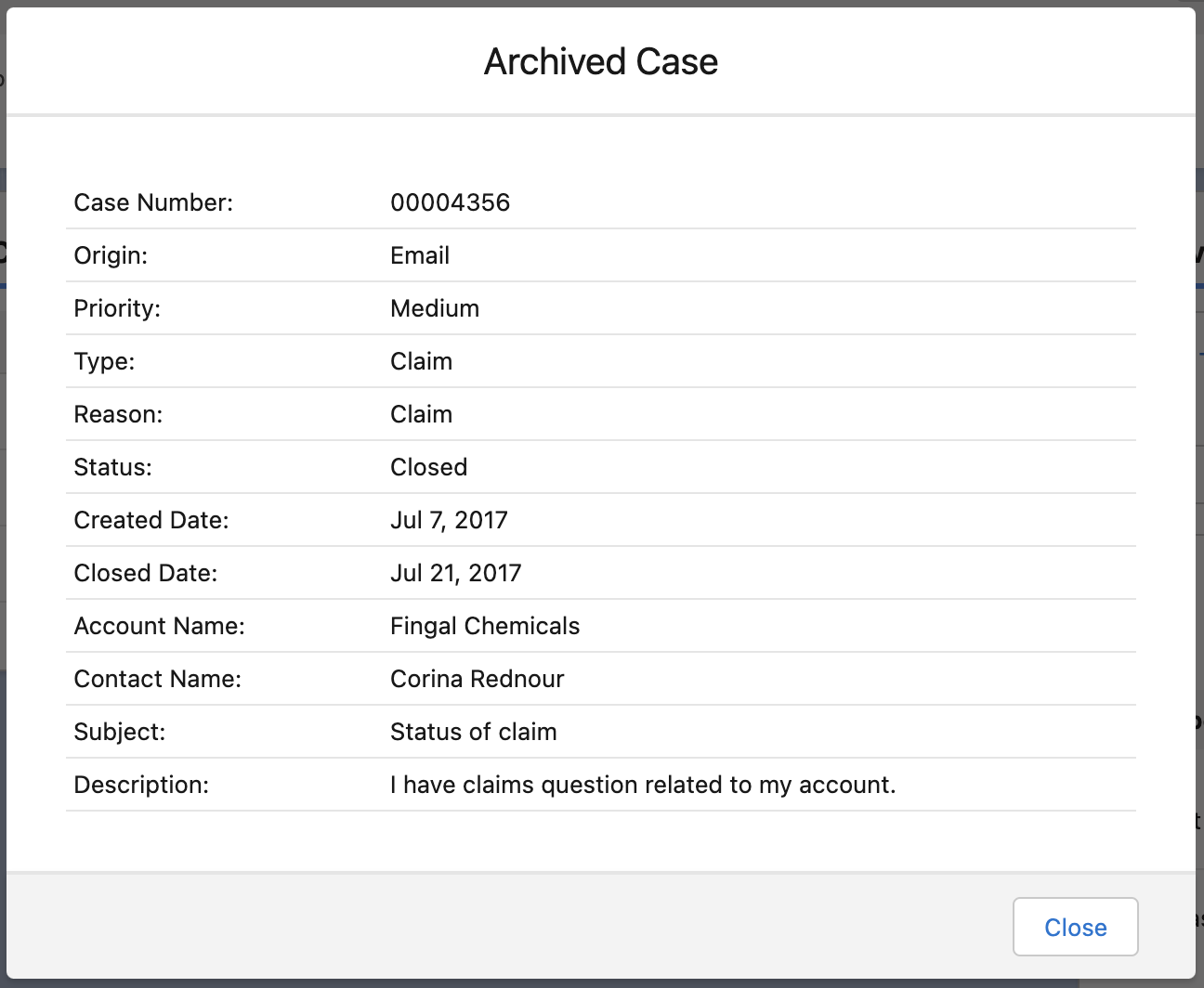
Account 记录中已归档的 Cases 相关列表界面:

使用 Big Object 要考虑的一些因素:
- 每个组织只能创建 100 个 Big Objects. 字段的限制与自定义对象的限制类似,并取决于你的组织的许可类型。
- Big Objects 只支持对象和字段级别的安全。
- Big Objects 可以在 Einstein analytics 中使用,但不能用于搜索和 report builder.
- 在向一个 Big Objects 写入数据时,最好的做法是有一个重试机制,直到你从 API 或 Apex 方法中得到一个成功的结果。
- 你可以使用
deleteImmediate()方法删除大对象中的数据。 - Big Objects 不支持事务。如果试图使用 sObject 上的 trigger,flow 等来读取或写入 Big Objects 数据,请使用
Asynchronous Apex(Future Methods, Batch Apex, Queueable Apex, Scheduled Apex), 通过异步写入,你可以更好地处理数据库生命周期事件。
